Před půl rokem mi Honza Mayer řekl, že budou pod záštitou FIT VUT a MUNI organizovat konferenci čistě o datové analytice. Žádné plané řeči o big data, ale praktické ukázky oblastí, kde analytika jasně prokazuje své přínosy. Těšil jsem se o to více. S týmem z KISKu sehnali spoustu zajímavých řečníků.
Sepsal jsem pár svých poznatků z každé přednášky konference DataConf2014. Nevysvětluji hlavní obsah přednášky, ale útržkovitě píši jen, co mne trklo do ucha.
Michal Buzek (Seznam): Data ve službách Seznamu
Vstávání v pět ráno a cestování z Prahy do Brna s sebou nese daň pozdních příchodů. Bohužel jsem nestihl více než poslední dvě minuty. Za tu dobu Michal stihl popsat, kdo všechno využívá v Seznamu výstupy z GoodData, že na počátku sloužily hlavně pro top management a teď pomáhají při řízení obchodních aktivit. To jste již možná četli v rozhovoru s Petrem Šimečkem na blogu Kebooly.V druhé otázce Michal zmínil, jak Seznam v rámci svého sběru dat o návštěvnících svých webů používá dva typy behaviorálních dat:- krátkodobé údaje s platností zhruba 2 hodiny – na kterých webech Seznamu se zrovna návštěvník nachází,
- dlouhodobé údaje s překvapivě krátkou dobou 14 dní – z toho čerpají průkaznější zájmy návštěvníků o různá témata.
Vojta Roček (Rockaway): Praxe
Ve svém povídání Vojta představil praktické věci, které mu pomáhají s datovou analytikou.
- Bavil se hodně o SQL jako naprostém základu, který už 40 let definuje práci s daty. Stačí jednoduché příkazy, na všechno ostatní máte StackOverflow.
- Ze zkušeností v Keboole a Rockaway zmínil, že v BI projektech není pochopení klientova byznysu to nejdůležitější a raději interpretaci dat nechával na klientovi. ETL procesy jsou alfa a omega BI. Proto Keboola svou službu Connection staví právě na perfektně zvládnutých procesech získávání a zpracování dat. Nahrání do GoodData je už jen třešnička. Tím je pak pravidelné nahrávání dat jednodušší.
„Pokud chcete dělat složité věci, jděte dělat tam, kde ujel vlak: to je např. bankovnictví“ – Vojta Roček
- Krásná charakteristika big data: pokud stávajícími prostředky nezvládáte zpracování současných dat.
- Proč firmy investují do big data: šéfíkové se bojí, že v datech je něco, co teď neví a mohli by být ztrapněni, pokud by to neobjevili.
- Tomáš Čupr řešil výběr KPI a projekt v GoodData ještě předtím než spustil projekt Dámejídlo.
Jakub Mráček (NášStát.cz): Ani opendata nezachrání svět (ale mohou ho výrazně zlepšit)
Dřívější propagátor otevřených dat nadhodil mnoho myšlenek o tématech i mimo opendata.Třeba o (ne)schopnosti informačních systémů spolupracovat se sebou. V IT by mělo jít o konvergenci – ať se systémy a data pospojují . Otevřená data k tomu mohou být prostředkem.
Nádherná IT konvergence v podání @jakubmracek :) #DataConf14 pic.twitter.com/0Cdes8RbKS
— Vojta Roček (@VojtaRocek) November 22, 2014
Lidé, kteří jsou informacemi zahlceni či přehlceni, mají tendenci přestat informace přijímat zcela. Což je pak bohužel taktika nejen ruské propagandy.
Ind Sugata Mitra, který se zabývá účinným vzděláváním, navrhl pro výuku angličtiny dětem praktický postup, jak děti nechat testovat své znalosti, aniž by je k tomu někdo nutil.
Jakub Mráček učí na gymnáziu chemii a informatiku – a právě tam dává základy práce s daty. Mimo jiné studentům ukazuje Google Fusion Tables. Jinak ale zmínil, že pojem digital natives je mýtus. Že ze třídy bývá jen jeden student velmi schopný využívat počítač. Desetina je pak totálně tragická a neumí počítač ani zapnout.
Veronika Bulková (MDT): Data pro život
Celá medicína je o datech. Lékař je de facto informační systém, který sesbírá (nebo přes vyšetření nechá sesbírat) data o pacientovi, zkombinuje je a určí diagnózu a postup léčby.Bohužel data zatím pomáhají výrazně méně, než by si Veronika představovala. Poukázala proto na oblasti, kde by to šlo vylepšit v první řadě:- zpracování poznatků lékařské vědy – vychází tuny učebnic, časopisů, impaktových článků a balastu, ale je těžké v nich najít vhodné poznatky. Když se lékař zajímá o aritmii, chtěl by, aby mu systém vytáhl seznam nejnovějších poznatků v této oblasti.
- Nemocniční a ambulantní systémy.
- Obrazy – RTG, CT, angiografie.
- Diagnostické softwary – už teď fungují na základě Bayesovské statistiky.
- Přenos dat od pacienta – e-health

V rámci jedné nemocnice si kliniky často nemohou čumět do spisů. Ochrana osobních údajů to nedovoluje. Přístupné jsou pouze výsledky laboratorních testů.
Zdravotní pojišťovny jsou zahlceny a nehledají fraud zbytečných vyšetření. Opakované návštěvy pacienta ve více klinikách se stejným problémem se zatím nepodchycují.
Existují balíčky PACs pro integraci obrazových podkladů do stávajících systémů. Často jsou licence na ně dražší než hardware samotný
Personál pečuje o pacienta jen zhruba 19 % z pracovní doby. Jinak jim hodně času zabírá administrativa.
https://twitter.com/…874443255808
Lékaři často pracují jen s tím, co viděli nebo s tím měli zkušenost. Jakékoliv pre-analýzy by jim měly pomoci. Např. identifikace rizikových faktorů a korelace v datech.
Veronika se věnuje telemedicíně – přístrojkem si lidi mohou měřit EKG v přirozeném prostředí a firma MDT z toho pak dělá vyšetření. V roce 2014 zpracují 4,5 milionu EKG snímků.
Jsem rád, že v Brně univerzity hodně tlačí na aplikace matematických metod v biologii, biostatistiku a jiné hezké multidisciplinární obory.
Adam Herout (Angelcam): Bezpečnostní kamery jako zdroj dat
Adamova firma angelCam zkouší nad kamerovými daty i nesupervizované učení. Na škole se podílí na zajímavých výzkumech.Ukázal také výstupy, jak kamerou zabírají ulici a sledují auta. Z toho pak identifikují nejen značky vozů, ale také modely (Fabia z určitého roku) a varianty (hatchback, combi).

Co z toho je tvář? Viz dřívější video z Devel.cz.
Existuje sada trénovacích obrázků ImageNet. Nad ImageNet se dají trénovat klasifikátory a sledovat, u kterých typů obrázků jsou výsledky nejsnažší a nejtěžší. Také jde o studnici zdrojů na výzkumy klasifikace obrázků.
Příklad využití:- Kdo chodí do obchodů: jsou to kravaťáci nebo skejťáci v mikině?
Michal Koščík (PrF MU): Právní minimum datového analytika aneb Jak se nebát žalob a nenechat se okrást
Na Právnické fakultě se nikdo datovou analytikou nezabývá. Nemá to svou oborovou komoru, není to moc stanovené.V zákonech jsou ale obecnější principy – získávání a zpracování informací, ukládání do databází a tvorba s šířením výstupů.
Michal zajímavě popsal, která z těchto částí je či není ochráněna právem. Nezmiňoval konkrétní čísla zákonů a paragrafy, ale oblasti, na které je třeba si dát pozor.
Lépe je ošetřeno, že není možné zastřelit jelena na akrobatické dráze.
Právo nechrání myšlenku samotnou, ale její objektivní vyjádření (např. sepsaným článkem či postupem) ano.Práva třetích osob
- ochrana osobních údajů
- správce (je povinností správce opatřit si souhlas se zpracováním osobních údajů),
- zpracovatel (nestará se o tento souhlas)
- práva pořizovatelů databází
- obchodní tajemství – jen když se smluvně stanoví mlčenlivost a pokuty
Zacházení s databází
- originální – licence, chrání se organizace (ne data)
- neoriginální – zužitkování (zpřístupnění, prodávání) nebo vytěžování (podstatné části, zkopírování ven)
Igor Szöke (FIT VUT): Extrakce informací z řeči
Ze záznamu zvuku se dá vytěžit velké množství vlastností:- Identita člověka
- Pohlaví
- Obsah
- Věk
- Telefon – kudy linka tekla, jaké kodeky používali
- Čím byl hovor nahráván
- Prostředí hovoru
- Jazyk
- AM akustický model
- slovník (tahá z fonémů slova)
- LM jazykový model
- získává slova, časování a pravděpodobnosti (+ paralelní hypotézy)
- HMM (skryté Markovovy řetězce) jsou starší přístup
- GMM (gaussian mixture models)
- neuronové sítě
Přístupy, jak dosáhnout vyšší kvality:Neurony by @IgorSzoke #DataConf14 #epic pic.twitter.com/zxKZztEUDP
— Veronika Neničková (@iVerNen) November 22, 2014
- přidávat více dat (vyplatí se ta další data získávat?)
- lepší algoritmy
- ideálně spojit oba přístupy (je tam však nelineární závislost kvality modelů na množství dat a kvalitě algoritmů
Igor měl přednášku na Barcampu 2011 Dolování informací z řeči aneb „co ani Google neumí“.
Michael Stencl: Když BI dává smysl…
Michal s Jirkou Tobolkou udělal praktickou ukázku rychlého založení projektu v GoodData, nalití dat z Twitteru, tvorba jednoduchých reportů i náhled na XAE (alespoň jednoduchou lineární regresí).Parádní, že se to stihlo během necelé hodiny. I když GoodData až moc neobjektivně pročpívala celou konferencí od rána do večera, myslím, že to zcela zaslouženě. V Reporting Services od Microsoft SQL Serveru byste mezitím stihli leda tak zjistit, že si knihovnu pro Twitter sami nedoinstalujete.
https://twitter.com/…513850728449
Mezitím Michal povídal o různých problémech tradičního BI a udělal také pořádek v pojmech Business Intelligence, Data Discovery a Knowledge Discovery.
Obecné problémy tradičního BI dle výzkumu v článku What Agile Business Intelligence Really Means.- 20% of data has errors in it (accuracy)
- 50% of data is inconsistent (consistency)
- It typically takes 7 days to get data to the end user (timeliness)
- It isn't possible to do a cross-database query on 70% of company data (scope)
- 65% of the time, executives don't receive the data they need (fit)
- 60% of the time, users can't do immediate online analysis of data they receive (analyzability)
- 75% of new key information sources that surface on the Web are not passed on to users within the year (agility)
- Pojem POC = Proof of Concept.
- sezónní data
- jak distribuovat léky proti alergiím po celém planetě
- věřit analytikovi
- řídit se jeho údaji
Základní nástroje pro EDA (exploratory data analysis)
- histogram
- pareto
- scatter plot
- parallel coordinates

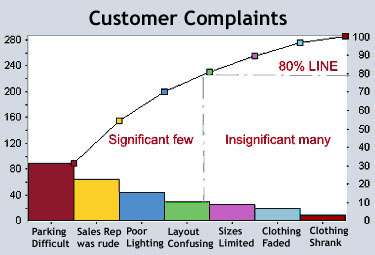
Scatter plot (korelační diagram, bodový graf)
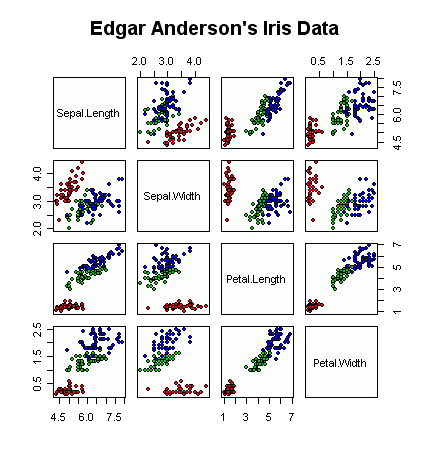
Parallel coordinates (v češtině Rovnoběžné souřadnice)

Součásti BI
- querying
- reporting
- OLAP
- alerty
Fáze Business Analytics
- Descriptive analytics – is about the past (reports, queries)
- Predictive analytics – predikce - is about the future (forecasting predictions)
- Prescriptive analytics – provides advice based on predictions (optimizations and simulations)

Prý nejlepší doporučovací firma je Ayata.
Doporučovací systém Amazonu byl v článku z roku 2001. Patent hýr. Asi v tom žádné nové terno nevymyslíte.Základní metody pro doporučování
- Factor analysis
- Matrix decomposition (slideshare s Mahoutem)
- Matrix factorization model (odkaz, tutoriál, pdf)
- Minimizing cost function (asi jsem nepochopil; cost funkce je základem strojového učení obecně)
- Usage-based MD mining (pdf 1, pdf 2)
- Např. objeví se peak v reportu
- GoodData pak rozpadne peak a ukáže, proč se to stalo

Michal Illich (Wikidi): Deep learning
Obdobná Michalova prezentace jako už jinde dříve.Seznam: poslední odkaz z homepage na novinky prý zkoušeli personalizovat.

Tesla dá autopilota na dálnice, nikoliv do městského provozu.

Tři důvody, proč deep learning prospívá
1. hloubka sítí – umožněna vyšším výkonem CPU/GPU a pár triky
How do you use GPUs to scale up Deep Learning? Bryan's meetup talk explains! https://t.co/uKOySUgnMC
— Andrew Ng (@AndrewYNg) August 4, 2014
2. využití neoznačených dat
Princip: autoenkodére, nauč se, co je tam důležité.
Odkaz na Stanford. A ještě jeden pro kurz, kde se probírají autoenkodéry.
3. odolnost proti přeučení- Pojem dropout
- Aby se síť nespoléhala, že se z konkréntích hodnot dá něco odvodit
Výsledky deep learningu
kategorizace obrázků- v roce 2011 9,5 % správnost rozpoznání
- deep learning ze Stanfordu 18 %
- snižuje se chybovost: tradiční metody 27 %, deep learning 18,5 %
Michalovy výzvy
- mít data nestačí.
- použivejte je.
- kreslit barevné grafy je základ, nikoliv plné využití dat.
- teprve až se udělá změna/rozhodnutí
- strojové učení by mělo urychlit tato rozhodnutí
- např. zaměřením se na konkrétní uživatele
- strojové učení
- nechte stroje samotné najít si vztahy v datech
- najít společné vlastnosti
- kde může student pracovat se strojovým učením na reálných projektech
- kaggle
- vlastní projekty
- akcelerátor
- na univerzitě
- v pár českých firmách
- spojovali s tweety o konkrétní firmě
- predikce vývoje
- statisticky signifikantní výsledky ve směru vývoje
- ale poplatky za akciové obchodování to kazí
- to myslím odpovídá závěrům spolumajitele RSJ Libora Winklera, který v rozhovoru uváděl, na jak brutálně malých maržích při obrovských vstupech a riziku fungují. Evropská daň za finanční transakce by je zničila.
Martin Hlosta: OUAnalyse: Odhalování rizikových studentů v distančních kurzech na Open University
Kniha Think Stats
V rámci akce se představil český překlad knihy Think Stats: Pravděpodobnost a statistika pro programátory. Je volně ke stažení na adrese http://bit.ly/thinkstats_cs.Kniha ‚Think Stats: Pravděpodobnost a statistika pro programátory‘ v českém překladu a zdarma: http://t.co/jehFliiNPJ #DataConf14
— Pavel Jašek (@paveljasek) November 22, 2014
Na konferenci byl i první výtisk na prolistování. I v počtu dvou stovek účastníků tam přes celý den vydržel.

Jak vidíte, konference byla pořádná darda inspirace. I když se v oboru pohybuji dlouho, ujasnění některých souvislostí se mi dost hodilo. A z obrázků a odkazů vidíte, že jsem si začal hledat další související témata.
Moc díky Honzovi Mayerovi a jeho týmu, že tuto akci pořádali.
Aktualizováno 12. prosince o videa ze všech přednášek.